IMDB Movie Data
Full Recipe¶
Shared by: Michael Aglietti
Explore a standard graph data set using Quine to combine data from separate sources, then generates a new event stream from the combined data.
IMDB Movie Data Recipe
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 | |
Scenario¶
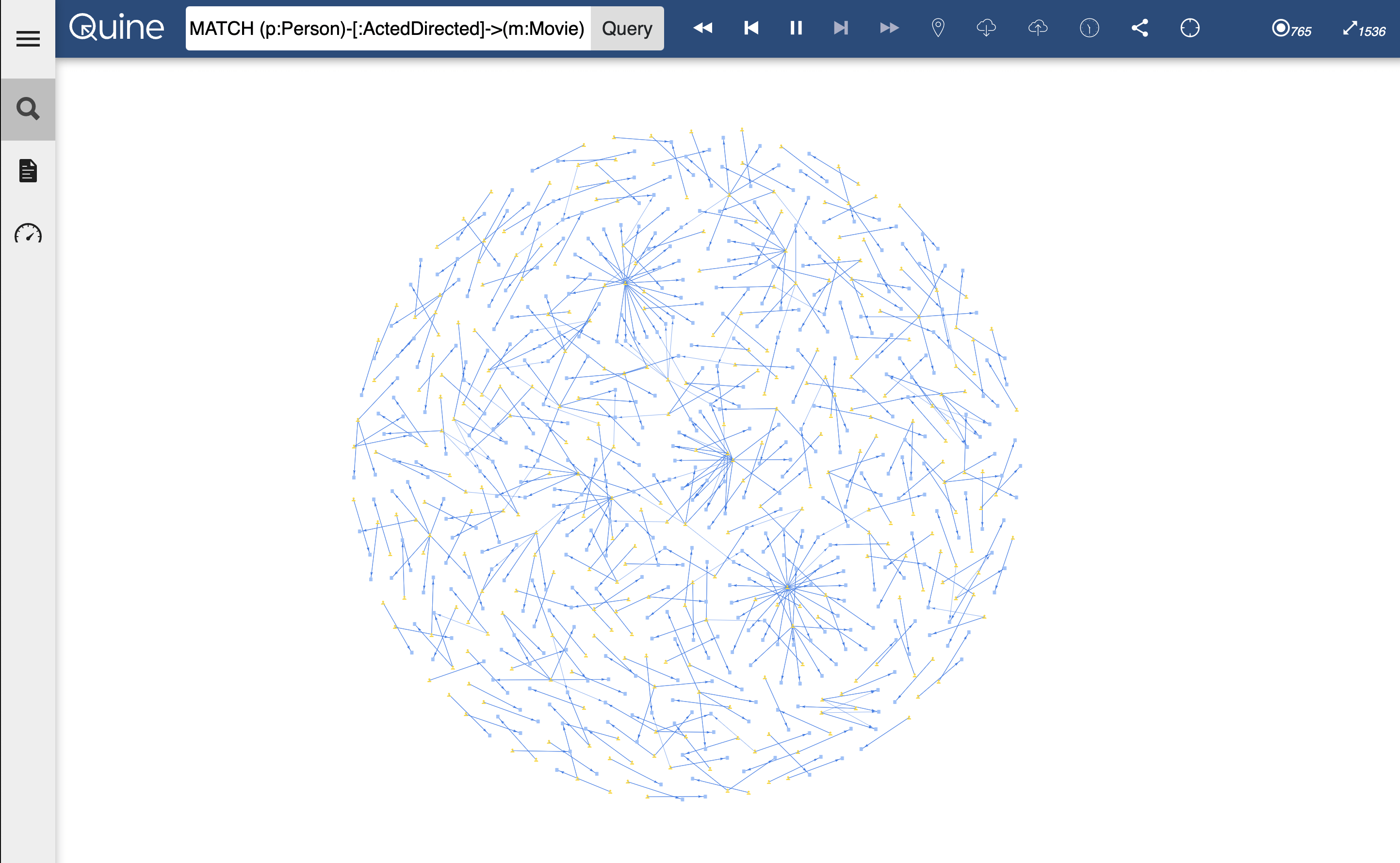
In this scenario, Quine combines data from multiple CSV files into one graph. As the graph is formed, a standing query matches and reports every instance of when a person is both the actor and director of a movie.
Sample Data¶
The sample data for this recipe is provided in two csv files that were exported from a relational database.
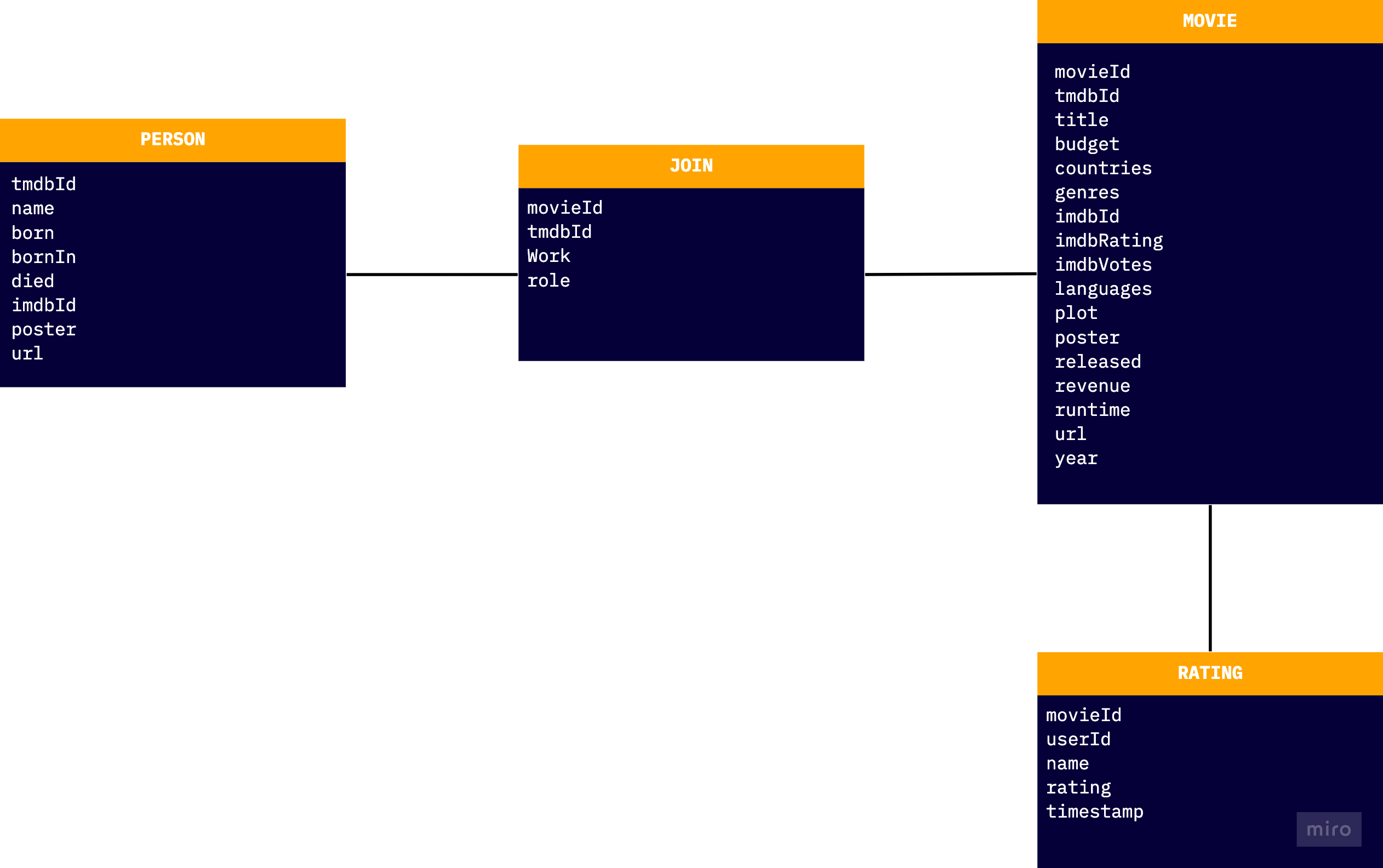
File 1: movieData.csv contains the Person, Movie, and Join rows.
File 2: ratingData.csv contains rows of ratings.
Click on the buttons above to download the sample data into the same directory where Quine will be run.
How it Works¶
This recipe parses the CSV files using ingest streams. We used multiple ingests streams to parse the movieData.csv file to highlight how the Cypher acts on each data structure. Creating a single ingest stream for the movie data would be more efficient.
The recipe ingests the CSV files to create the following graph shape.
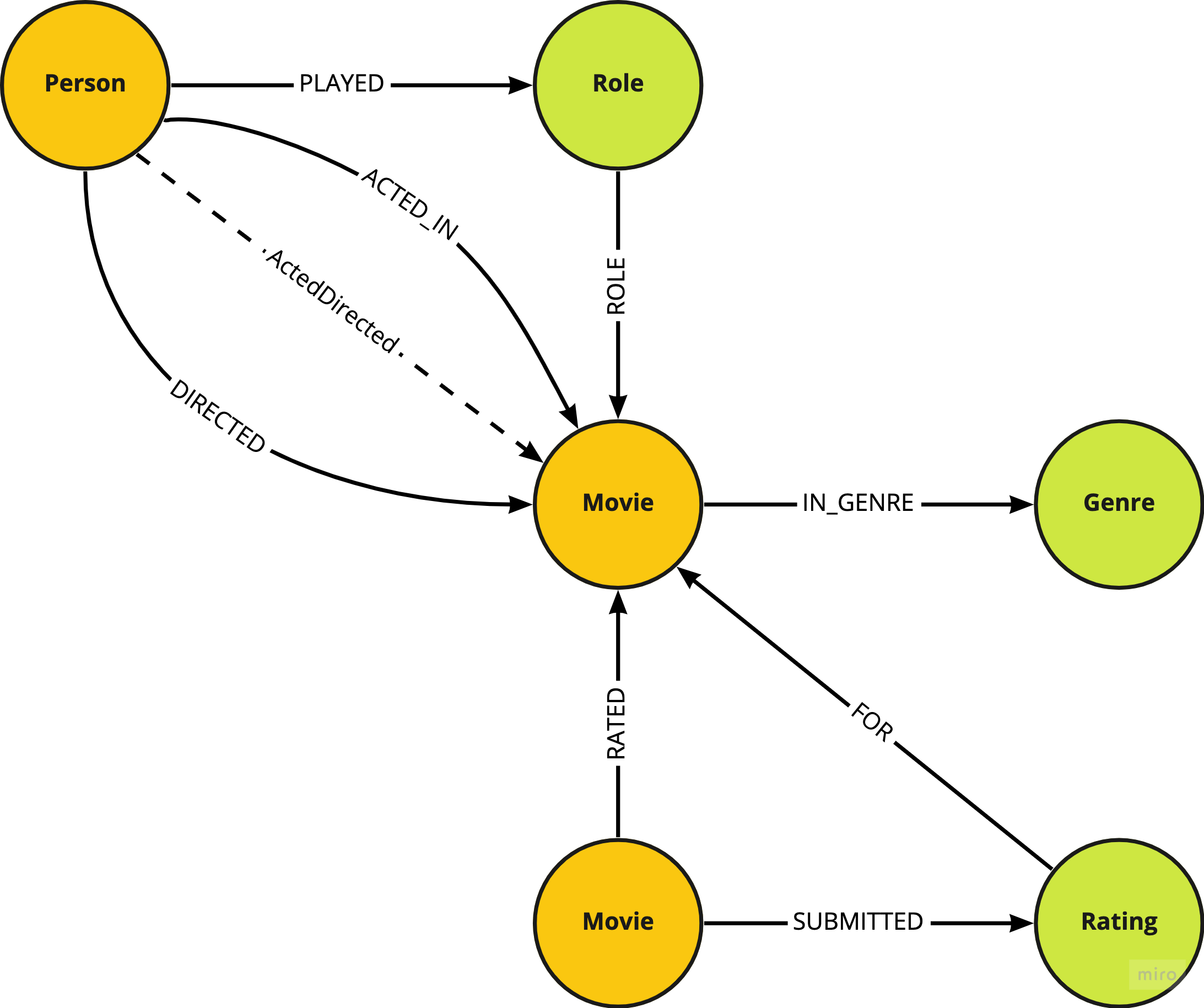
Movie and Genre Nodes¶
The first ingest stream matches the movieData.csv file's rows containing Movie entities. These rows are parsed, turned into Movie and Genre nodes, and filled with properties. Genre nodes are connected to Movie nodes in the graph.
- type: FileIngest
path: $movie_file
format:
type: CypherCsv
headers: true
query: |-
WITH $that AS row
MATCH (m)
WHERE row.Entity = 'Movie'
AND id(m) = idFrom("Movie", row.movieId)
SET
m:Movie,
m.tmdbId = row.tmdbId,
m.imdbId = row.imdbId,
m.imdbRating = toFloat(row.imdbRating),
m.released = row.released,
m.title = row.title,
m.year = toInteger(row.year),
m.poster = row.poster,
m.runtime = toInteger(row.runtime),
m.countries = split(coalesce(row.countries,""), "|"),
m.imdbVotes = toInteger(row.imdbVotes),
m.revenue = toInteger(row.revenue),
m.plot = row.plot,
m.url = row.url,
m.budget = toInteger(row.budget),
m.languages = split(coalesce(row.languages,""), "|"),
m.movieId = row.movieId
WITH m,split(coalesce(row.genres,""), "|") AS genres
UNWIND genres AS genre
WITH m, genre
MATCH (g)
WHERE id(g) = idFrom("Genre", genre)
SET g.genre = genre, g:Genre
CREATE (m:Movie)-[:IN_GENRE]->(g:Genre)
{
"type": "FileIngest",
"path": "$movie_file",
"format": {
"type": "CypherCsv",
"headers": true,
"query": "WITH $that AS row\nMATCH (m) \nWHERE row.Entity = 'Movie' \n AND id(m) = idFrom(\"Movie\", row.movieId)\nSET\n m:Movie,\n m.tmdbId = row.tmdbId,\n m.imdbId = row.imdbId,\n m.imdbRating = toFloat(row.imdbRating),\n m.released = row.released,\n m.title = row.title,\n m.year = toInteger(row.year),\n m.poster = row.poster,\n m.runtime = toInteger(row.runtime),\n m.countries = split(coalesce(row.countries,\"\"), \"|\"),\n m.imdbVotes = toInteger(row.imdbVotes),\n m.revenue = toInteger(row.revenue),\n m.plot = row.plot,\n m.url = row.url,\n m.budget = toInteger(row.budget),\n m.languages = split(coalesce(row.languages,\"\"), \"|\"),\n m.movieId = row.movieId\nWITH m,split(coalesce(row.genres,\"\"), \"|\") AS genres\nUNWIND genres AS genre\nWITH m, genre\nMATCH (g) \nWHERE id(g) = idFrom(\"Genre\", genre)\nSET g.genre = genre, g:Genre\nCREATE (m:Movie)-[:IN_GENRE]->(g:Genre)"
}
}
Person Nodes¶
The second ingest stream matches the movieData.csv file's rows containing Person entities. These rows are parsed, turned into Person nodes, and filled with properties.
- type: FileIngest
path: $movie_file
format:
type: CypherCsv
headers: true
query: |-
WITH $that AS row
MATCH (p)
WHERE row.Entity = "Person"
AND id(p) = idFrom("Person", row.tmdbId)
SET
p:Person,
p.imdbId = row.imdbId,
p.bornIn = row.bornIn,
p.name = row.name,
p.bio = row.bio,
p.poster = row.poster,
p.url = row.url,
p.born = row.born,
p.died = row.died,
p.tmdbId = row.tmdbId,
p.born = CASE row.born WHEN "" THEN null ELSE datetime(row.born + "T00:00:00Z") END,
p.died = CASE row.died WHEN "" THEN null ELSE datetime(row.died + "T00:00:00Z") END
{
"type": "FileIngest",
"path": "$movie_file",
"format": {
"type": "CypherCsv",
"headers": true,
"query": "WITH $that AS row\nMATCH (p) \nWHERE row.Entity = \"Person\" \n AND id(p) = idFrom(\"Person\", row.tmdbId)\nSET\n p:Person,\n p.imdbId = row.imdbId,\n p.bornIn = row.bornIn,\n p.name = row.name,\n p.bio = row.bio,\n p.poster = row.poster,\n p.url = row.url,\n p.born = row.born,\n p.died = row.died,\n p.tmdbId = row.tmdbId,\n p.born = CASE row.born WHEN \"\" THEN null ELSE datetime(row.born + \"T00:00:00Z\") END,\n p.died = CASE row.died WHEN \"\" THEN null ELSE datetime(row.died + \"T00:00:00Z\") END"
}
}
Role Nodes¶
The third ingest stream matches the movieData.csv file's rows containing Join entities that have Acting in the Work column. These rows are parsed, turned into Role nodes, filled with properties, and connected to the graph. Additionally, the ACTED_IN relationship is set between the Person and Movie nodes.
- type: FileIngest
path: $movie_file
format:
type: CypherCsv
headers: true
query: |-
WITH $that AS row
WITH row
WHERE row.Entity = "Join"
AND row.Work = "Acting"
MATCH (p), (m), (r)
WHERE id(p) = idFrom("Person", row.tmdbId)
AND id(m) = idFrom("Movie", row.movieId)
AND id(r) = idFrom("Role", row.tmdbId, row.movieId, row.role)
SET
r.role = row.role,
r.movie = row.movieId,
r.tmdbId = row.tmdbId,
r:Role
CREATE (p:Person)-[:PLAYED]->(r:Role)<-[:HAS_ROLE]-(m:Movie)
CREATE (p:Person)-[:ACTED_IN]->(m:Movie)
{
"type": "FileIngest",
"path": "$movie_file",
"format": {
"type": "CypherCsv",
"headers": true,
"query": "WITH $that AS row\nWITH row \nWHERE row.Entity = \"Join\" \n AND row.Work = \"Acting\"\nMATCH (p), (m), (r) \nWHERE id(p) = idFrom(\"Person\", row.tmdbId)\n AND id(m) = idFrom(\"Movie\", row.movieId)\n AND id(r) = idFrom(\"Role\", row.tmdbId, row.movieId, row.role)\nSET \n r.role = row.role, \n r.movie = row.movieId, \n r.tmdbId = row.tmdbId, \n r:Role\nCREATE (p:Person)-[:PLAYED]->(r:Role)<-[:HAS_ROLE]-(m:Movie)\nCREATE (p:Person)-[:ACTED_IN]->(m:Movie)"
}
}
Directed Nodes¶
The fourth ingest stream matches the movieData.csv file's rows containing Join entities that have Directing in the Work column. These rows are parsed and the DIRECTED relationship is created between the Person and Movie nodes.
- type: FileIngest
path: $movie_file
format:
type: CypherCsv
headers: true
query: |-
WITH $that AS row
WITH row WHERE row.Entity = "Join" AND row.Work = "Directing"
MATCH (p), (m)
WHERE id(p) = idFrom("Person", row.tmdbId)
AND id(m) = idFrom("Movie", row.movieId)
CREATE (p:Person)-[:DIRECTED]->(m:Movie)
{
"type": "FileIngest",
"path": "$movie_file",
"format": {
"type": "CypherCsv",
"headers": true,
"query": "WITH $that AS row\nWITH row WHERE row.Entity = \"Join\" AND row.Work = \"Directing\"\nMATCH (p), (m) \nWHERE id(p) = idFrom(\"Person\", row.tmdbId)\n AND id(m) = idFrom(\"Movie\", row.movieId)\nCREATE (p:Person)-[:DIRECTED]->(m:Movie)"
}
}
Rating Nodes¶
The fifth ingest stream matches rows from the ratingsData.csv file to create User and Rating nodes, fill them with parameters, and connect them into the graph.
- type: FileIngest
path: $rating_file
format:
type: CypherCsv
headers: true
query: |-
WITH $that AS row
MATCH (m), (u), (rtg)
WHERE id(m) = idFrom("Movie", row.movieId)
AND id(u) = idFrom("User", row.userId)
AND id(rtg) = idFrom("Rating", row.movieId, row.userId, row.rating)
SET u.name = row.name, u:User
SET rtg.rating = row.rating,
rtg.timestamp = toInteger(row.timestamp),
rtg:Rating
CREATE (u:User)-[:SUBMITTED]->(rtg:Rating)<-[:HAS_RATING]-(m:Movie)
CREATE (u:User)-[:RATED]->(m:Movie)
{
"type": "FileIngest",
"path": "$rating_file",
"format": {
"type": "CypherCsv",
"headers": true,
"query": "WITH $that AS row\nMATCH (m), (u), (rtg) \nWHERE id(m) = idFrom(\"Movie\", row.movieId)\n AND id(u) = idFrom(\"User\", row.userId)\n AND id(rtg) = idFrom(\"Rating\", row.movieId, row.userId, row.rating)\nSET u.name = row.name, u:User\nSET rtg.rating = row.rating,\n rtg.timestamp = toInteger(row.timestamp),\n rtg:Rating\nCREATE (u:User)-[:SUBMITTED]->(rtg:Rating)<-[:HAS_RATING]-(m:Movie)\nCREATE (u:User)-[:RATED]->(m:Movie)"
}
}
Acted and Directed¶
A standing query detects when an actor (Person) has both the ACTED_IN and DIRECTED relationship to the same Movie.
When a pattern match is found, the ActedDirected relationship is created between the Person and Movie nodes in the graph, and an alert is written into the ActorDirector.jsonl file.
- pattern:
type: Cypher
mode: MultipleValues
query: |-
MATCH (a:Movie)<-[:ACTED_IN]-(p:Person)-[:DIRECTED]->(m:Movie)
WHERE id(a) = id(m)
RETURN id(m) as movieId, id(p) as personId
outputs:
set-ActedDirected:
type: CypherQuery
query: |-
MATCH (m),(p)
WHERE id(m) = $that.data.movieId
AND id(p) = $that.data.personId
WITH *
CREATE (p:Person)-[:ActedDirected]->(m:Movie)
RETURN id(m) as movieId, m.title as Movie, id(p) as personId, p.name as Actor
andThen:
type: WriteToFile
path: "ActorDirector.jsonl"
{
"pattern": {
"type": "Cypher",
"mode": "MultipleValues",
"query": "MATCH (a:Movie)<-[:ACTED_IN]-(p:Person)-[:DIRECTED]->(m:Movie) \nWHERE id(a) = id(m)\nRETURN id(m) as movieId, id(p) as personId"
},
"outputs": {
"set-ActedDirected": {
"type": "CypherQuery",
"query": "MATCH (m),(p)\nWHERE id(m) = $that.data.movieId \n AND id(p) = $that.data.personId\nWITH *\nCREATE (p:Person)-[:ActedDirected]->(m:Movie)\nRETURN id(m) as movieId, m.title as Movie, id(p) as personId, p.name as Actor",
"andThen": {
"type": "WriteToFile",
"path": "ActorDirector.jsonl"
}
}
}
}
The output object contains information about the match and the nodes matching the query.
{
"meta": {
"isPositiveMatch": true,
"resultId": "d2008617-cc5c-4f81-8472-f3db277f8da2"
},
"data": {
"Actor": "Clint Eastwood",
"Movie": "Unforgiven",
"movieId": "4a6d64c8-9c90-3362-b443-4d2e7b2fb9d1",
"personId": "4638a820-3b68-3fc7-9fa7-341e876b701e"
}
}
Running the Recipe¶
java \
-jar quine-1.6.2.jar -r movieData.yaml\
--recipe-value movie_file=movieData.csv \
--recipe-value rating_file=ratingData.csv
Tip
This recipe will create an ActorDirector.jsonl file in the local directory that you should remove before each run. We found it easier to launch Quine using the following shell script so that we didn't forget to clean up output from previous runs.
#!/bin/bash
[ -f ActorDirector.jsonl ] && rm ActorDirector.jsonl
java \
-jar quine-1.6.2.jar -r movieData.yaml\
--recipe-value movie_file=movieData.csv \
--recipe-value rating_file=ratingData.csv
Launching Quine directly or using run-recipe.sh will produce output similar to this.
❯ ./run_recipe.sh
Graph is ready
Running Recipe: Ingesting CSV Files
Using 6 node appearances
Using 8 sample queries
Running Standing Query STANDING-1
Running Ingest Stream INGEST-1
Running Ingest Stream INGEST-2
Running Ingest Stream INGEST-3
Running Ingest Stream INGEST-4
Running Ingest Stream INGEST-5
Quine web server available at http://localhost:8080
INGEST-1 status is completed and ingested 74090
INGEST-2 status is completed and ingested 74090
INGEST-3 status is completed and ingested 74090
INGEST-4 status is completed and ingested 74090
INGEST-5 status is completed and ingested 100005
| => STANDING-1 count 491
Summary¶
Be sure to open Quine in your browser using the URL provided in your terminal window. Several sample queries are ready for you to use in the Exploration UI query bar. Click on the query bar and launch the queries by pressing the Query button.
Tip
Submit text queries with Shift+Enter to avoid the Exploration UI sending back an error.
| Sample Query | Type | Description |
|---|---|---|
| Sample of Nodes | Node | Return a sample of nodes from the graph |
| Count Nodes | Text | Count the types of nodes in the graph |
| Count Relationships | Text | Count the types of relationships in the graph |
| Movie Genres | Node | Return the movie genres nodes from the graph |
| Person Acted In a movie | Node | Return all of the actor nodes from the graph |
| Person Directed a movie | Node | Return all of the director nodes from the graph |
| Person Acted In and Directed a movie | Node | Return all of the actor and movie nodes where the actor also directed |
| User Rated a movie | Node | Return all of the rating nodes from the graph |
The results from the Person Acted In and Directed a movie create an interesting shape you can explore further with your queries.